Data Science: A 21st Century Discipline for Everyone
Harvard Business Review: Data Scientist, The Sexiest Job of the 21st Century
https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century
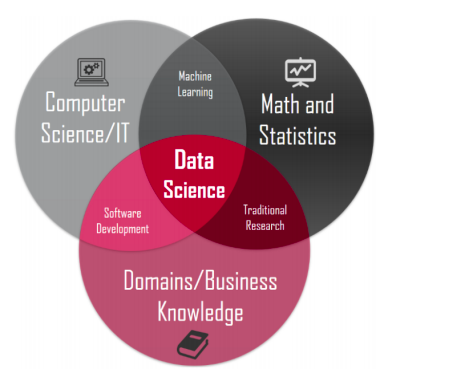
It is our belief that everyone must be literate of the capabilities of Data Science. While Data Science may not solve all of the world’s problems, it will help us all better understand and analyze the world’s problems especially as more devices collect more data. As this Venn Diagram displays, Data Science requires skills in multiple disciplines: (1) Computer Science and IT, (2) Mathematics and Statistics and (3) Domain Specific Knowledge.
https://towardsdatascience.com/introduction-to-statistics-e9d72d818745
With these three requirements, it will be rare to find a pure Data Scientist. Most Data Scientists will be experts in a specific domain such as medicine, cyber-security, finance, government, the environment and more. Given their domain specific expertise, students of Data Science will branch out into specific tracks to become:
– Medical Data Scientists pioneering the field of personalized medicine
– Public Health Data Scientists fighting pandemics like COViD-19
– Cyber Security Data Scientists securing our IT infrastructures
The list of possible applications of Data Science is endless. Due to the evolving importance of Data Science, virtually every college and university is beginning to offer degrees in Data Science.
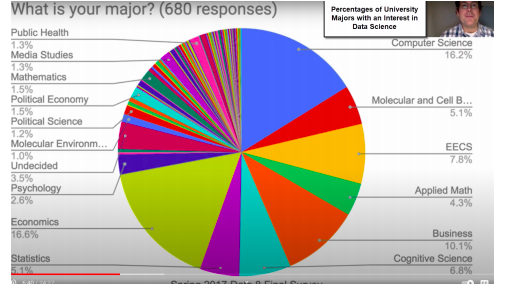
If you select a top American University and google for its Data Science program, very likely a Data Science Initiative for that university will appear. The following pie chart reflects the interest in Data Science by undergraduate university major:
Source: UC Berkeley Data 8 – Introductory Data Science Program
YouTube: Data 8 Reflections by UC Professor John DeNero (24 min. 27 sec)
Leading the trend in Data Science education is the Cal Berkeley Computer, Data Science and Society Department (https://data.berkeley.edu/) As its name implies, Data Science has wide ranging applications for all of society. It is for this reason that universities like Cal Berkeley are reaching out to high school students to introduce them to the broad applications and bright future of Data Science. With this DS4HS program, we want to join this effort to educate high school students in Data Science as well.
Now, please read and review the following three foundational lessons that provide contextual background for the Cal Berkeley Unboxing Data Science (BUDS) program.
Lesson One: Attaining Literacy with the Underlying
Technologies of Data Science
Hardware, Software, Operating Systems, the Cloud and More
Before students begin their Data Science studies, it is important for them to be literate with the underlying fundamentals of computer science and information technology (IT).
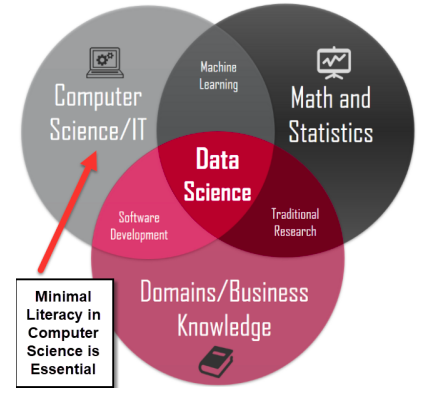
All aspects of Data Science depend on an underlying computer infrastructure that young Data Scientists must be literate of.
Consider the following:
- Collected data must be stored in a file that ultimately resides on some form of hardware: a disk drive, a USB stick, etc.
- Collected data must be validated and indexed by a software program. Software programs rely on both operating systems and ultimately hardware to run.
- Both the data file and the software program must be stored in a folder on a computer.
- These files and folders will ultimately reside on some type of storage device: a hard drive, USB stick or something in the Cloud.
With this said, consider the following as a starting point to attain a minimal degree of literacy on the underlying computer technologies of Data Science. When reviewing the following, make reference to the overall design of your own SmartPhone. While the following may apply to any computer system – your SmartPhone, your laptop computer, a Web Server in the cloud or even
an AppleWatch – let’s make our primary reference our smart phone since we all have one.
Every computer system including your SmartPhone is made up of two categories of computer technology:
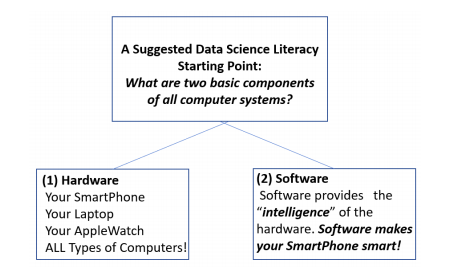
As we attempt to stress above, while software requires hardware to operate, computer software is the key component that brings intelligence to computer hardware. Our DS4HS program is much more oriented towards software than hardware. While a Data Scientist needs to know a bit about hardware, a Data Scientist needs to know ALOT about software.
To stress the importance of the role of software, consider the following tagline of one of the most successful Silicon Valley Venture Capitalists, Andreessen-Horowitz “Software is eating the world”:

Professional Data Scientists are focused on software oriented tasks. In today’s world, if Data Scientists need more hardware resources, they will consider paying for more hardware on an as needed basis in the cloud. More details on the exact meaning of the “the cloud” will be provided later in this course.
At this point in our introductory session, let’s focus on two fundamental categories of software:
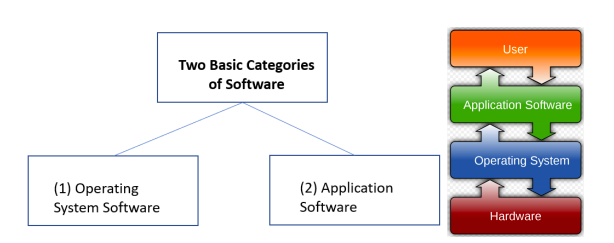
Source: https://en.wikipedia.org/wiki/Software
99% of all smart phones in the world use either the Apple iOS operating system or the Google Android operating system,
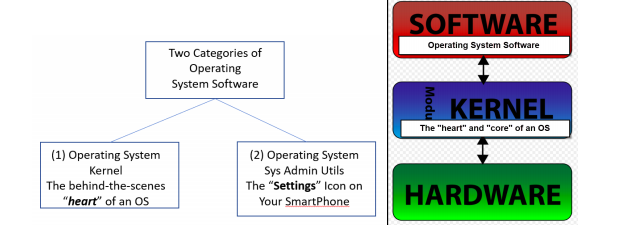
Source: https://en.wikipedia.org/wiki/Kernel_(operating_system)
NOTE: If you use an Android Smartphone, you are using a device that is powered by the LINUX operating system “kernel”.
Introducing “The Cloud”
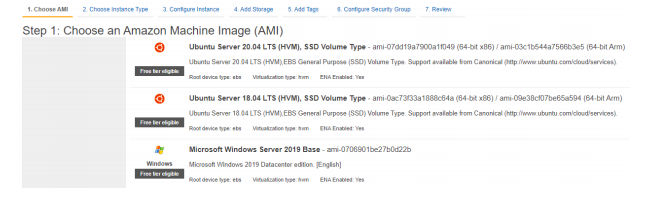
While these are important terms and concepts a budding Data Scientist needs to be literate with, it is important to stress that in the future it is likely that Data Scientists will encounter these concepts and resources in “the cloud”. When these resources are used in the cloud, you do not purchase hardware and operating systems, you essentially rent them. Here are two screen shots from Amazon Web Services that show the first two steps of provisioning a virtual computer system or “virtual machine” (VM) in the AWS cloud: (Step 1) select your operating system and (Step 2) select the underlying hardware you want AWS to allocate to your virtual machine:
Step 1: Select your operating system using an Amazon Machine Image (AMI). Make note that of the three AMI choices in the screenshot, two use the LINUX operating system and one uses the Microsoft Windows operating system.
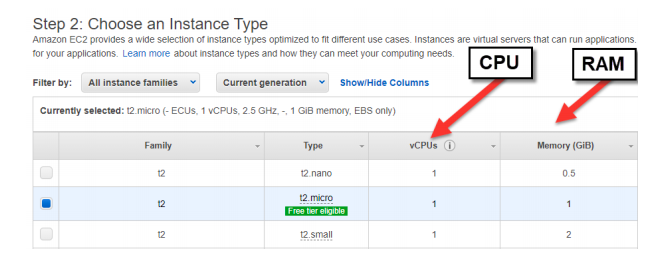
Step 2: Select your Amazon Elastic Computing 2 Instance Type (your hardware resources):
It is extremely important to note that when you provision a cloud based virtual computer system or “virtual machine” (VM), you are setting up your virtual machine in a specially constructed building called a “Data Center” to securely and reliably run your virtual machine. In upper right corner of an Amazon Web Services management console, is a drop down menu that will indicate what Data Center you are currently viewing along with Amazon Data Centers located all over the world:
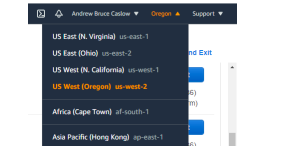
How to create Virtual Machines in AWS will be covered later in this course.
Consider the CPU, Memory, Storage and Operating System on Your Smart Phones and
Your Smart Watches…. and Your Fitbits… and Your Smart TV
All of these devices possess these basic computer hardware components: A CPU, Memory, Storage, Device Input/Output, Network Connectivity (Bluetooth/WIFI/Cellular) and an Operating System.
To gain insights on these components on your SmartPhone, perform the following:
If you have an Apple iPhone, access SETTINGS=>GENERAL==>About
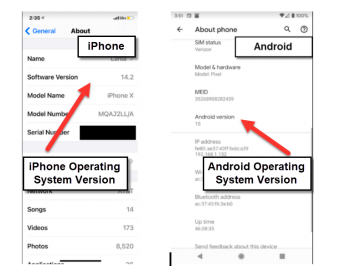
The display above shows your Apple Model Name and iOS Operating System version. As seen above, Android phones can display similar hardware and OS information as well.
To gain insights on how these systems are assembled and to determine what you can do with a given system’s operating system, go to web-sites such as the following:
https://developers.google.com/
https://developers.apple.com/
https://developer.samsung.com/
Or simply google phrases like “CPU used by the iPhone”, “Operating System Used by Apple Watch”, “Operating System Used by Fitbit”.
For a high school student attempting to gain some background information of the basics of computers and operating systems, consider the following: a larger CPU and more memory generally results in a faster operating computer that can perform more tasks at once. Think about creating the most amazing gaming PC imaginable: you would want this PC configured with a fast CPU or multiple CPU’s, lots of RAM and even a specialized graphics coprocessor.
However, with these enhancements, especially with a larger CPU, it is likely that the system will generate more heat and require more power (a longer lasting battery). Balancing these types of issues are what make SmartPhones and other Smart Devices modern marvels, Many of them use specialized “System on a Chip” technologies that are custom made to maximize device performance and minimize issues such as heat generation and power consumption.
Conclusion
This lesson attempted to provide a starting point for Data Science studies by modularizing and compartmentalizing computer systems using general categories such as “hardware and software”, “operating system software and application software, etc. Such modularization and compartmentalization is a recurring theme in overall computer design and software design. In fact, a common expression in software development is: “Divide, Conquer and Combine”.
In the field of Data Science, computer systems can be viewed as “data collectors”, “data storage devices” or “data processing/data analysis devices” We must keep focused on the real value of using computer systems in the field of Data Science: to collect, process, store, analyze and visualize data. While there are many exceptions to the following, let’s consider this for now: we
use our SmartPhones, SmartWatches, Fitness Trackers, etc to collect data and we use virtual machines in the cloud to store, process and analyze our data. While we may wear these devices and carry them everywhere, they still are computers with hardware, an operating system and application software. So much of the data these devices generate is sent on to the cloud for storage and processing. While we are focused on studying Data Science in this DS4HS program, we must be literate of the underlying computer infrastructure that supports our Data Science activities: hardware, software, operating systems, the cloud, etc.
In the next two lessons, we will build on what was covered in this lesson. In Lesson Two, we will focus on the topic of software with an emphasis on application software and software packaging. In Lesson Three, we will focus on (1) collecting data from a range of computer devices and (2) on how to store and analyze the collected data on a separate computer – from a laptop to a virtual machine in the cloud.
Supplemental Content: DO NOT FORGET TO WATCH THESE VIDEOS!
code.org: How Computers Work with Bill Gates – Intro (1 minute 20 seconds)
code.org: Hardware and Software with Bill Gates and friends (5 minutes and 22 seconds)
Lesson Two: Software and Software Packaging
In the previous Lesson, we started our journey in Data Science with an overview of the underlying computer technologies that will make Data Science come alive: computer hardware, software, operating systems and the Cloud.
In this Lesson, we will build on the foundation of the previous lesson and focus on two topics: software and software packaging. Notice in the Venn Diagram below, the explicit role of Software Development.
https://towardsdatascience.com/introduction-to-statistics-e9d72d818745
There is no way around it: to be a Data Scientist you must be literate in software development and issues related to software development. The more skill you have in the field of software development, the more empowered you will be as a Data Scientist.
And very likely, you already have laid a good foundation for writing software in all of the math classes you have ever taken. Over the years math teachers have told you, “Show all of your work and do not skip any steps”. This mindset is essential for becoming a Data Science computer programmer. Furthermore, instead of you writing out each step in a math problem one line at a time with a pencil, you are able to type out each line of software code on your computer. This will allow you to cut and paste lines of code with ease. You can’t do that with a pencil while showing all steps in solving a math problem!
Reference: How Programming Supports Math Class
Writing Software Is About Thinking Logically to Perform Problem Solving
Introducing the Term “Algorithm”
At the heart of any software program are highly structured line-by-line steps for the computer to perform a specific outcome or solve a specific problem. This highly structured logical flow of steps encoded in a computer program is called an algorithm.
https://en.wikipedia.org/wiki/Algorithm
A Rhetorical Question Comparing Cells in the Human Body to Software Files on a
Computer System
Let’s now consider the following rhetorical question: (1) Is the human body composed of only one big cell? OR (2) Is the human body composed of trillions of cells of a wide variety? Of course the answer is #2. The human body is composed of trillions of cells of a wide variety: nerve cells, blood cells, skin cells, the list goes on and on. Furthermore, every cell contains
DNA, “the software of life”.
Just as the human body is made up of a massive collection of cells, computer systems are composed of thousands and sometimes millions of software files. Some of these software files are for operating system functions. Others files are for specific apps. All of these software files are treated as “software packages” and they are saved onto the computer system’s file system. Think about all of this the next time you see “Download Updates” on your SmartPhone. These “updates” that are downloaded to your SmartPhone are actually updated software files containing updated lines of computer code.
Finally, all software files contain software code. The code can be software programming languages such as C, Python, Java, JavaScript, the list goes on and on. While there is a wide variety of programming languages, one shared characteristic of all programming languages is: they are logically structured into functions and procedures and use statements such as
if/then/else, while/do, etc.
Using your Elastic Mentor remote desktop, you can truly grasp this theoretical idea of a computer containing thousands if not millions of software files with the LINUX utility tree. The LINUX tree utility is installed on your Elastic Mentor remote desktop. Move around your remote desktop’s file system (or on any LINUX computer) and enter the command tree . (don’t forget the dot). You will see a spectrum of directories with lots of files in each directory. You will appreciate how complex computer systems have become.
Now, consider the following image:

https://economictimes.indiatimes.com/small-biz/
In this image, we see SmartPhone App icons floating above a SmartPhone screen. Imagine this: one of these icons could be your very own Data Science SmartPhone app! Very soon, you will be performing a series of Python programming hands-on exercises. By writing a Python program, you are on your way to writing your own app! In this course, you will start small by writing and understanding simple Python scripts using supporting tools like Jupyter Notebooks. Over time, your once simple Python scripts can evolve into powerful full-featured SmartPhone apps.
Viewing Software from the Perspective of Software Packaging
Perform the following: Access the Elastic Mentor:
Click on the following link: https://max.elasticmentor.com/b/bru-zzc-05u-inj
Open a LINUX terminal screen on your Elastic Mentor Remote-Desktop.
Then enter dpkg -l (this is the letter l and not the number 1).
Then enter: dpkg -l tree
Then enter: dpkg -L tree (you see the specific files related to the tree software package)
The dpkg utility displays both summaries and details of what software packages are installed on a given LINUX system. The dpkg utility clearly displays how software packages can be composed of hundreds of files spread over multiple directories in a file system.
Viewing Software from the Perspective of One Line of Code at a Time
In the previous lesson, we discussed software from a very conceptual level. We reviewed major categories of software such as operating system software versus application software.
In this lesson, we will start with viewing software as a logically organized set of lines of code using specific words such as “if/then/else” or “while/do”. To get us started, consider the following game-like computer programming interface from the Google Blockly education project :
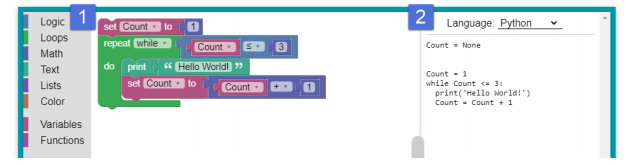
Source: Google Blockly https://developers.google.com/blockly
On the left hand side (1), we see computer code presented as multi-colored puzzle pieces that connect together. Each color represents a different category of computer code: logic statements, loops, math operations, functions and more. One the right hand side (2), we see the underlying lines of code that are generated by the Google Blockly GUI interface. Google Blockly can
auto-generate code for multiple languages including Python and JavaScript.
Just as this useful Blockly interface reflects, computer software, at a very fundamental level, is a file containing logically structured lines of code that use a limited but very specialized vocabulary that include terms such as “if/then/else”, “while/do”, “repeat/until”, etc.
With this said, consider the following progression:
Computer software is:
- lines of code written in a specific programming language
- saved in a file usually with an extension to indicate the programming language used *.py for Python, *.js for JavaScript, *.c for C, *.java for Java
- saved in a folder or file directory
- contained within an Operating System file system
- residing on some form of hardware storage medium such as a disk drive or USB stick
If you are brand new to programming and you are learning how to program using tools such as Blockly or Code Academy, you may not realize that the code you are generating needs to be saved to a file on an operating system in order to run your computer program any time in the future. If you don’t save your code, it will be lost forever.
Consider the following flow chart focused on the question, “What computer programming language should I learn?”
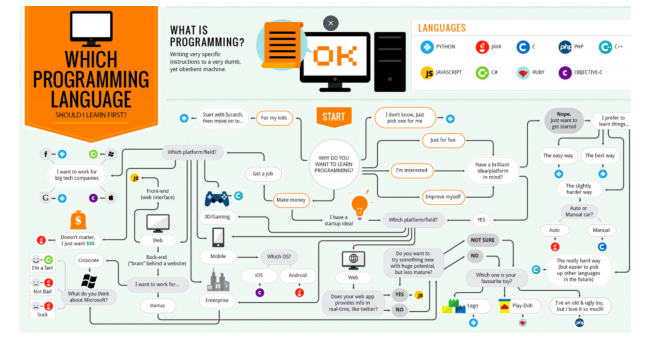
https://codeburst.io/what-programming-language-should-i-learn-f3f164ca376c
As the chart above reflects, there are several computer programming languages (9 are featured in the chart above and there are many more). Regardless of which programming language you use, the following types of files will reside within your operating system file system:
1). Your Apps.
2). Multiple files (usually called packages, modules and libraries) containing the computer program itself.
3). Operating system files containing tools to manage both the computer program files you create yourself and the files containing the computer programming language “package” itself.
In summary, when you write your apps, you will be writing them within a software ecosystem that will include at least two components: (1) an underlying operating system to install the programming language in and (2) programming language software and all of its modules. Consider the following diagram: the Python programming environment itself is a set of software files that enable software developers to write computer programs in the Python language. Notice how Python points to three operating systems: Windows, Apple or Ubuntu LINUX. When you write Python programs, you must write them in “some” operating system. You must make an operating system choice. Take your pick: Windows, LINUX or Apple.
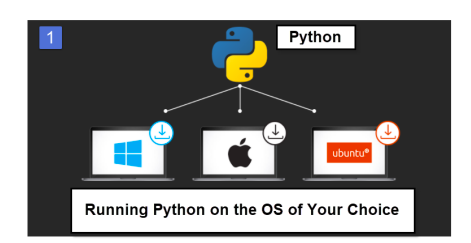
Source: Everything You Need to Know to Set Up Python in Any OS: Windows, Mac or LINUX
Once you have picked which operating system you want to write your Python programs for, you can then pick which Python modules you want to use to fast track your Python development. Python has thousands of modules to select from. Specifically, Python has a very rich set of Data Science modules as displayed in the screenshot below:
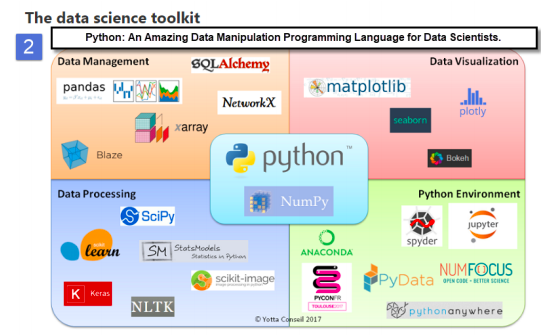
Source: https://atrebas.github.io/post/2019-01-15-2018-learning/
Also: Exploring the Python Eco-System
https://chanzuckerberg.com/eoss/proposals/ (Essential Open Source Software for Science)
As budding Data Scientists, you will not need to know how to develop and write software for operating system functions or programming language functions. You will stay focused on STEP ONE of your journey: writing and editing simple Data Science scripts in Python. Remember, becoming a Data Scientist is a lifelong journey. In this DS4HS Program, we are beginning at Ground Zero, We will start simple with simple Python scripts in Jupyter Notebooks and over time you will expand your understanding of this entire Data Science ecosystem.
For now, you will only need to know basic LINUX Operating System Administration commands such as:
- pwd to view your present working directory
- ls to see a list of files and directories
- cd to change to another directory
- cp to copy files from one directory to another
These commands will help you manage the files used by your programming language (modules and libraries) as well as the Data Science computer programs you write yourself.
Furthermore, you will use the following tools to help you get started in understanding and editing your own Data Science computer programs:
1). Jupyter Notebooks
2). Jupyter Labs (a Jupyter Notebook extension integrated with git functionality)
Use Github to Access a Massive Library of Working Code
When becoming literate with computer software in general and writing computer software in particular, it is helpful to have access to a repository of working code that you can download, read, review and actually deploy. Github provides this resource. The core content of this DS4HS course is downloaded from the github site of the University of California at Berkeley Unboxed Data Science (BUDS) program for high school students.
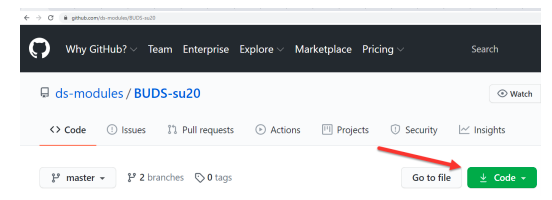
Students can access this github page at https://github.com/ds-modules/BUDS-su20 and click on the green Download Code button in the lower corner of the screenshot above. Once this button is clicked, students can copy the url: https://github.com/ds-modules/BUDS-su20.git and perform a git clone operation to download the entire BUDS courseware. In this course, we will perform this step on the remote desktop of every student using the Elastic Mentor.
Conclusion
Up to this point in our studies, Lessons 1 and 2 have outlined two of the underlying structural components of Data Science: (1) computer technology in general and (2) computer software – whether it is operating system software or application software. In the next lesson, we discuss “data”…. Yes, this is the very same “data” in the name Data Science! Just as computer software
is stored in files, data must also be stored in files or it risks being lost forever. While pre-packaged computer software can be easily re-installed if it is damaged, data cannot. Data must be protected and backed up constantly.
Based upon what was covered in this chapter regarding software and software packages, the following flow diagram outlines all of the key software used in this DS4HS program:
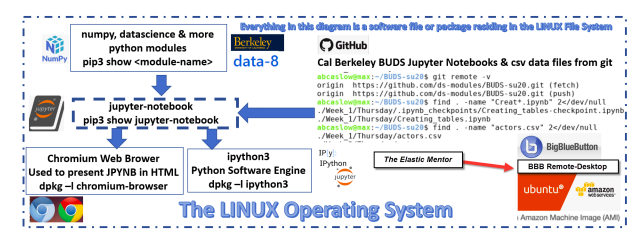
You may not understand this software flow diagram at this time. By the end of this DS4HS program, you will understand it completely. It is also worth noting that all of the software listed above is open source software. The open source community helps facilitate greater interoperability between software packages.
Lesson Three: Data and Common Data Formats
This Lesson examines the critical element of Data Science: D-A-T-A! Data has been called the “oil” of the 21st Century, the “raw material” of the 4th Industrial Revolution. Consider the following magazine cover from the Economist Magazine:

Next review the following graph listing the amounts of data being generated by Big Tech companies such as Google, Amazon, Facebook as well as from apps such as e-mail. Most shocking of all is this statement: “90% the world’s data was created in the last four years.” Virtually, all of the data referenced in the graph below can be classified as “user generated content”. https://en.wikipedia.org/wiki/User-generated_content
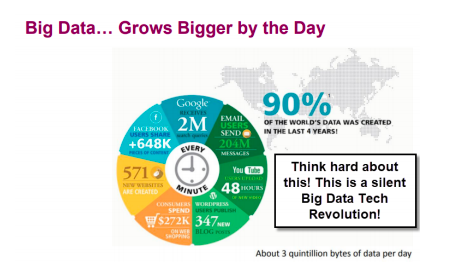
As a Data Scientist, you will need to feel comfortable with working with the following numbers measuring the amount of data collected for a specific study:
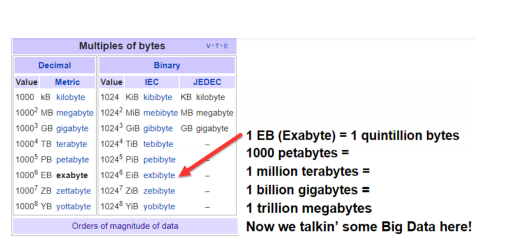
Think about all of the challenges of going through data at the Exabyte level. No laptop can save and store this amount of data. To move an Exabyte or more of data onto Amazon Web Services, AWS has a service called “Snowmobile”. With Snowmobile, AWS will send a tractor trailer to your site to collect this amount of data.

I am not kidding! Check out this 4 minute video:
https://aws.amazon.com/snowmobile/
While we want you to be aware of the potential and reality of organizations collecting and storing MASSIVE amounts of data. In this DS4HS program we are going to work with small amounts of data that will involve two common data formats: (1) csv and (2) JSON. The csv format is commonly used to download and upload data into spreadsheet software applications. JSON is commonly used with API’s. JSON also maps very well to Python Data Types. Since this is a DS4HS course, we are starting small and will be working with both csv and JSON data formats. We will be examining csv and JSON data formats extensively with Elastic Mentor labs later in this course.
Before we dive into our hands on labs, let’s all get synced up on some general principles of data.
Another Rhetorical Question
Consider the following rhetorical question:
1). A spaceship lands in your backyard and you take the one and only picture and video of this event with your SmartPhone. News spreads around the planet about what happened in your backyard. All news outlets from around the world know you have the only photo and video of the spaceship on your SmartPhone. If these facts were true, what would be worth $1 million+ dollars on your SmartPhone? (A) Your SmartPhone hardware, (B) Your SmartPhone Operating System, (C) Your SmartPhone Apps or (D) Your Smart Phone Data specifically the pictures of the spaceship that landed in your backyard? Answer: Your data: the picture of the spaceship.
If your SmartPhone was lost or destroyed, everything can be replaced except the data. Since you are a budding Data Scientist, the sooner you realize the precious value of data the better.
Data is precious and irreplaceable. It must be protected and backed up frequently.
Next, consider the following chart. Note the references to the interaction between a (1) SmartPhone’s Application Software and (2) the Data Generated by the App.
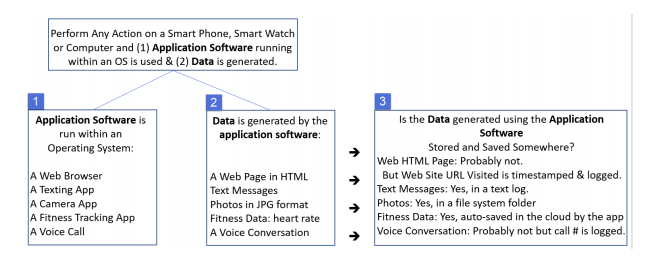
Where is your smartphone data stored?
● Text messages: in a text log file with each message time stamped
● Photos and Videos: in a folder on your smartphone with each photo and video stored in a separate file. The photos could have an extension of *.jpg and the videos and extension of *.mp4
● Music: in a folder on your smartphone with each song having an extension such as *.mp3
All of this data can be backed up onto a personal computer or even into the Cloud. This is very, very important: ALWAYS BACKUP YOUR DATA!!!
The Internet of Things and the Massive Amount of Data Generated by the Internet of Things
Review the following Economist Magazine cover on the Internet of Things:

Economist Magazine: September 14-20th, 2019
A major trend is to deploy new “machine-to-machine” services on the Internet via the Internet of Things. Reading about the Internet of Things can be an exciting supplement to this DS4HS course. However, in this DS4HS course we want to maintain as much hands-on learning as possible. Let’s stress that Internet of Things (IoT) devices will generate more data, lots of digital footprints, that will be collected and analyzed by Data Scientists in the future.
Hands-On Lab: Examine some log data with the LINUX commands: cat and grep
Click on the following link:https://max.elasticmentor.com/b/bru-zzc-05u-inj
Open a LINUX terminal screen and enter:
cd /var/log/bigbluebutton
Enter the following command:
cat bbb-web.log
You will see the entire BigBlueButton Web log. Enter the following command:
cat bbb-web.log | wc -l
You will see the number of lines in the BBB web log. Please write this number down.
Enter the following command:
cat bbb-web.log | grep Andrew
You will see only the lines in the log that contain the string Andrew.
Enter the following command:
cat bbb-web.log | grep Andrew | wc -l
You will see the number of lines in the BBB that contain the name Andrew. Notice that this number of lines is less than the total number of lines in the log.
Please review this sample of data from the bbb-web.log file:
![]()
Using regular expressions, the Python dictionary data structure (highlighted in yellow) can be extracted from this log entry.
Notice that it has some type of structure but the structure is not a commonly used data format such as csv or JSON. Using LINUX tools such as grep with regular expressions or the Python regular expression module, we can pull out the data from this log that we want. This will be a very important skill to have as a Data Scientist. Check out the following web-site to learn more about regular expressions: https://regex101.com/. Here is a quick and useful youtube video on regular expressions: Intro to Regular Expressions (20 minutes).
While working with JSON or csv data is much easier to work with compared to data from a log file such as the one displayed above. regular expressions can be used with a programming language like Python to grab the data you want as a Data Scientist and place the date into csv or JSON format.
Tables: The Most Common Form of Data in Introductory Data Science
According to the following Cal Berkeley Data Science course: “In most cases, when interacting with data you will be working with tables.”
https://github.com/ds-modules/data-4ac/blob/master/notebook1/notebook1.ipynb
The Exact Same Table Data in Three Different Data Formats Used in Data Science
Here are three samples of the exact same data in three separate formats: (1) a human readable table, (2) a csv file providing a more programmatic format and (3) a JSON format which maps directly to Python data structures such as lists and dictionaries.
A Human Readable Table – Generated by a Spreadsheet (Excel/GoogleSheets)
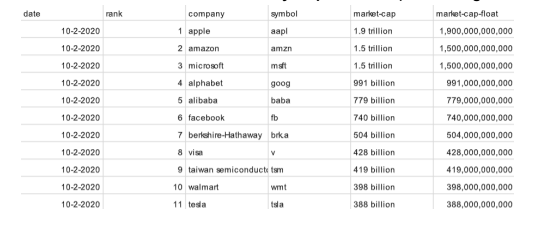
The Exact Same Data in CSV Format – Spreadsheets Can Save Data in CSV Format

The Exact Same Data in JSON Format: Perfect for Python!
A simple 10 line Python script can convert a csv file to JSON format.
The following JSON object maps to a Python List of Dictionaries

Also, using the Python PANDAS module (https://realpython.com/pandas-dataframe/) in a powerful learning environment such as Jupyter Notebooks, you can easily convert a csv file into a PANDAS table called a “Dataframe”:
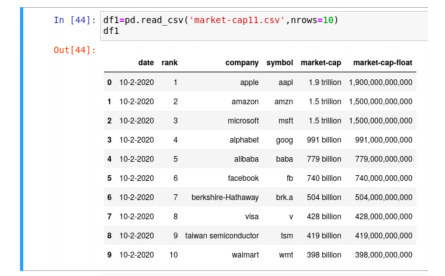
Finally, using the same Jupyter Notebooks environment and using other Python modules such as matplotlib, you can visualize your data in a wide range of different ways. Here is one example of a scatter plot from a Jupyter Notebook from the University of California Berkeley Unboxed Data Science (BUDS) program for high school students:
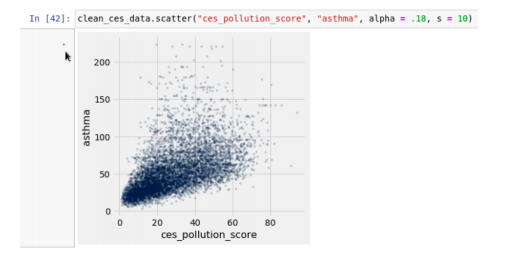
Source: BUDS-su20/week-4/Monday/Environmental-justice.ipynb
Conclusion
This lesson covered the subject of the very source of Data Science itself: D-A-T-A!
We now have the foundational knowledge to begin our comprehensive study of the fundamentals of Data Science. Given what we have covered in the last three lessons, we are ready to begin using:
the Ubuntu LINUX Operating System
the Python programming language with its Data Science and Data Visualization Modules
the Jupyter Labs/Jupyter Notebooks learning environment
git for saving and versioning our Python scripts and data files (git is built into Jupyter Labs)
the Elastic Mentor Remote Desktop Distance Learning System
We will use this environment to cover the Data Science content designed for high school students by the University of California Berkeley Unboxed Data Science (BUDS) program. BUDS is a five week long program that we will stretch out over 12 weeks.
Click here for more details on BUDS
Here is a great video on what BUDS is all about:
https://www.youtube.com/watch?v=d2EG3i2s7f8&feature=emb_title
Here is the github link to the BUDS course content:
https://github.com/ds-modules/BUDS-su20
As stressed over and over in the BUDS content, high school Data Science students will learn the Data Science Life Cycle:
- Conducting problem identification as questions or hypotheses
- Identifying data sources
- Conducting exploratory data analysis
- Statistical Modeling
- Using prediction and inference to draw conclusions
- Communication, Dissemination, and Decision
At the heart of this six step Data Science Life Cycle is Step Four: Statistical Modeling. In the upcoming modules, we will pay special attention to Statistical Modeling or “Building Data Models”. When we do so, we will constantly refer to the famous quote of the statistician George Box, “All models are wrong, but some are useful”.

This quote underscores the power and beauty of Data Science. Data Science Models will always need to be adjusted and refined. Oftentimes, Data Science Models will expose what was once thought to be random is actually pseudo-random as more data becomes available.
As a supplement to our DS4HS program, we will feature a complete data model called PatchSim from the University of Virginia BioComplexity Institute. An explanation of the PatchSim data model along with supporting Python code is available at https://github.com/NSSAC/PatchSim In 2020, PatchSim was used by the state of Virginia to model the spread and control of Covid-19 throughout the state.
At the end of the DS4HS program, you will migrate away from using the Elastic Mentor remote desktop to using your own system on either your laptop computer or in the cloud. However, remember that you can always come back to your Elastic Mentor remote desktop for lifelong learning as well as for software testing and evaluation.
So let us now begin our hands-on learning of Data Science. As it is said, that mathematics is not the study of numbers but the study of the relationship between numbers, we will see that Data Science is not the study of data but the study of relationships between data. We will start our journey with simple data analysis and manipulation tasks and build up to more complex tasks as the course progresses.
